Non importa se funziona, l’importante è che il vibe sia giusto!
L’idea è semplice: dentro un container Docker, l’agente si installa da solo tutto l’arsenale da vero reverse engineer, da radare2 a gdb, passando per binwalk, xxd e compagnia bella.
Poi prendi un binario, gli dici “ehi, analizza questo e dimmi come non farlo esplodere”, e lui inizia a produrre disassemblati, log e perfino un report PDF bello pronto. Perfetto da mostrare al capo oppure da usare per fare colpo con studentesse e studenti di ingegneria informatica.
Crack me, baby!
Per testare questa meraviglia gli ho fatto affrontare diverse challenge di crack-me. Spoiler: se l’è cavata niente male!
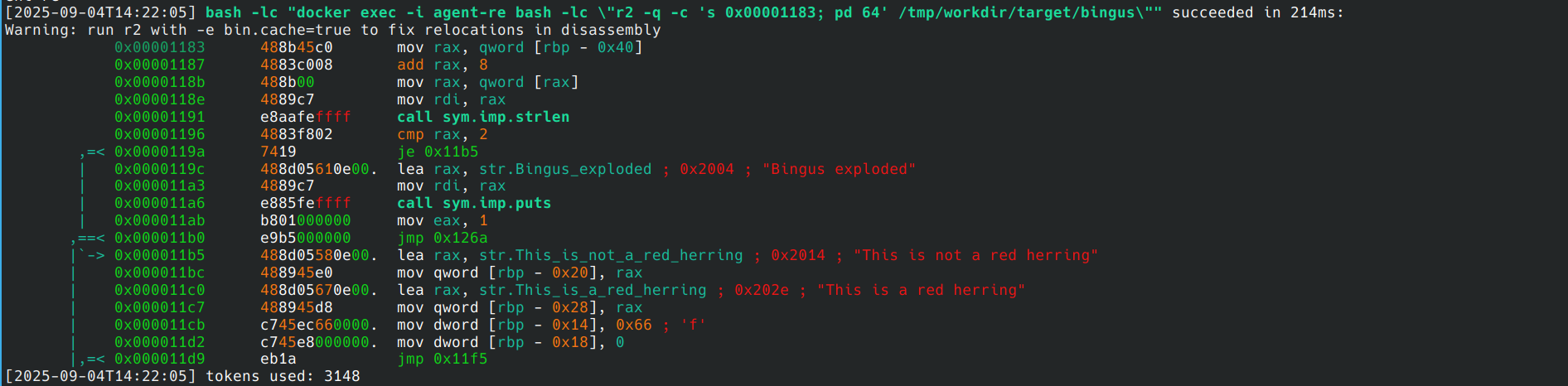
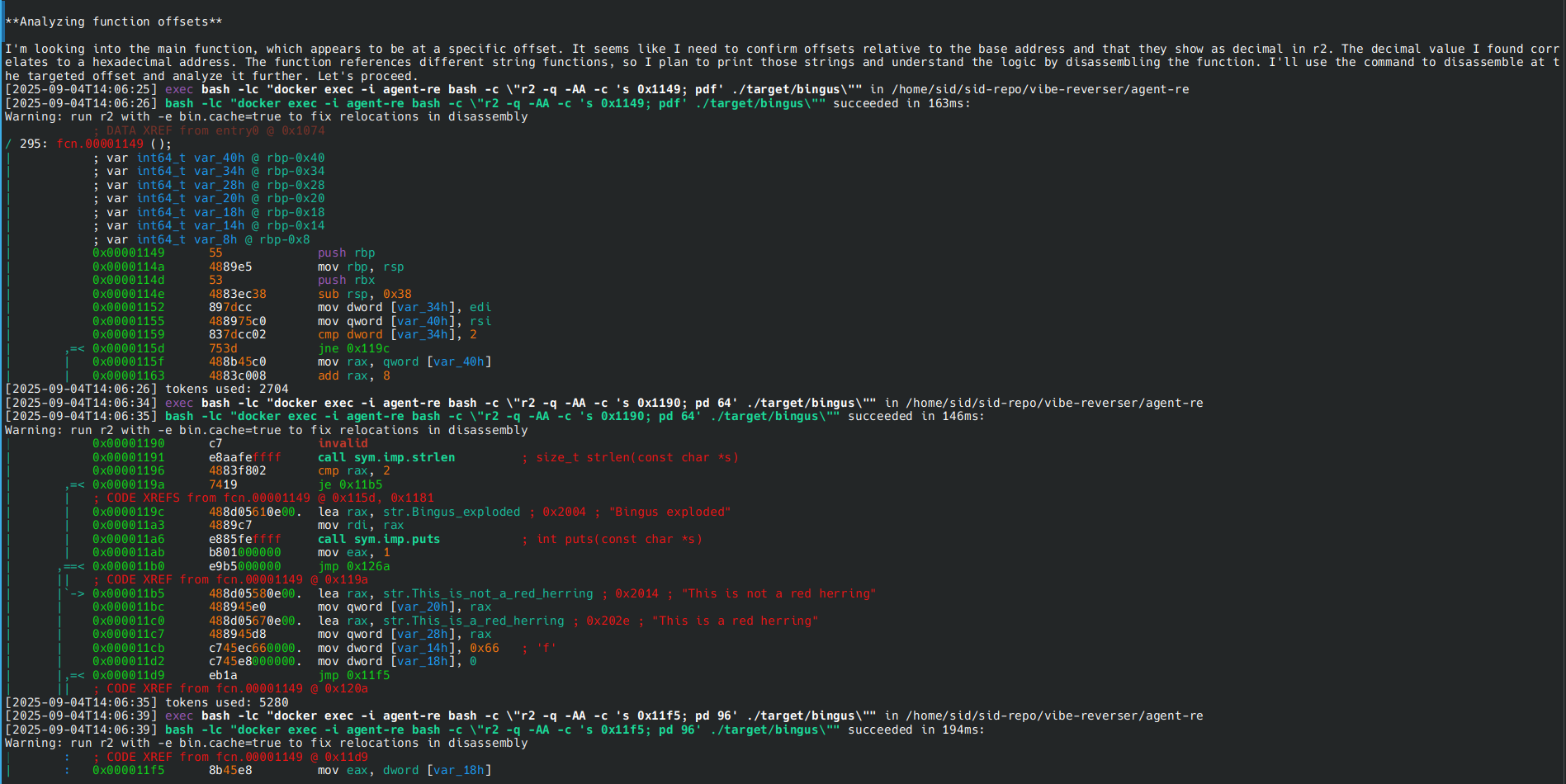
Prendiamo il classico esercizio della “bomba” da disinnescare.
Abbiamo un binario ELF strippato, quindi senza simboli di debug (già qui lo studente medio di ingegneria inizia a deprimersi), che quando lo lanci esplode subito con un bel messaggio: “Sono esploso!”. L’obiettivo? Farlo sopravvivere.
Ovviamente ci sono vari modi per riuscirci, ma la challenge chiede esplicitamente di non fare binary patching, ovvero di non girare i salti condizionali (JE , JNE, ecc). Quindi diciamo alla nostra creatura di non farlo. Bisognerà trovare una strada diversa, trovare una password, fare lib preloading, ecc, ma noi non gli diciamo niente di tutto ciò e lasciamo che trovi la sua strada (per l’inferno).
Avviamo l’agente dicendogli semplicemente:
Analyze the target file ./target/bingus and find a way to prevent it from exploding without a binary-patch.
Il fascino del caos incontrollato
A questo punto lui parte: tribola, disassembla, riflette e vomita a schermo tutto il vibe possibile, fino a mettere insieme la soluzione. Il tutto condito con un bel report ordinato.
Nel report ci rivela che la soluzione è lanciare il programma passandogli un parametro “pp” per non farlo esplodere, ed effettivamente è così.
Bello vero?
Se vuoi provarlo, trovi tutto sul mio GitHub. Prima di avviarlo leggiti il README, soprattutto il paragrafo “SECURITY”. Oppure fregatene: tanto lo sai già, l’importante è che il vibe sia giusto!
UnityWebData1.0 is a standard of data file used by WebGL games.
It is loaded along with the game binary and contains some resources like shapes, 3D objects, sounds, and so on.
Besides these resources, it may contains the Il2Cpp metadata that is useful to simplify the reverse engineer of the WebAsm code.
The IL2CPP (Intermediate Language To C++) is an alternative to the Mono backend. The IL2CPP backend converts MSIL (Microsoft Intermediate Language) code (for example, C# code in scripts) into C++ code, then uses the C++ code to create a native binary file.
This type of compilation, in which Unity compiles code specifically for a target platform when it builds the native binary, is called ahead-of-time (AOT) compilation. The Mono backend compiles code at runtime, with a technique called just-in-time compilation (JIT).
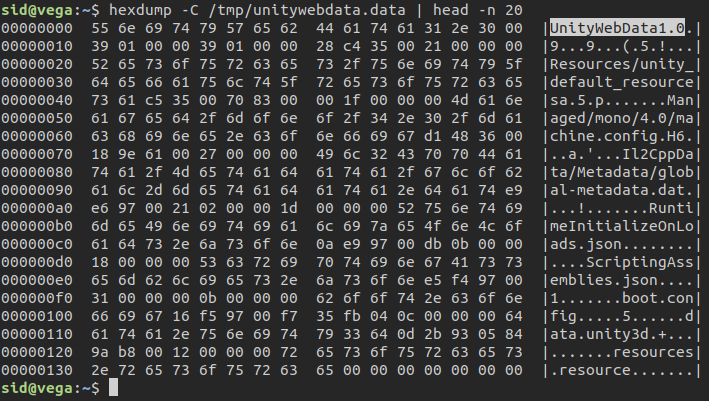
Popular disunity tool doesn’t handle this type of file, and binwalk or file(1) aren’t helpful this time, so we need another way to realize it.
To see if we are looking at a UnityWebData1.0 data file, simply check the header, which contains the string “UnityWebData1.0.”
UnityWebData1.0 file headerAs you can see “file” is not very useful this time
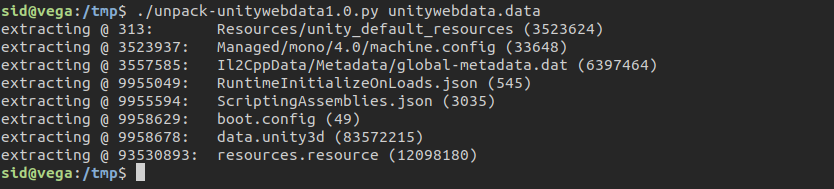
We can use a UnityPack python library via this small wrapper. It will create a folder with some files, named “extracted”. This is the usage:
L’app “Mastella” non ha nulla a che fare con l’Intelligenza artificiale e invia la posizione geografica all’insaputa dell’utente.
DISCLAIMER
Tutte le informazioni che troverete in questo post si basano su constatazioni oggettive, inconfutabili, e corredate di evidenza tecnica. Per questo motivo, alcuni passaggi possono risultare ostici ai non addetti ai lavori.
Chiunque, in qualsiasi momento, può verificarne la veridicità effettuando le stesse indagini in maniera indipendente.
La seguente analisi è perfettamente lecita e legale in quanto effettuata esclusivamente sul mio telefono e prende in esame l’applicazione “Mastella”, nella versione 6.32, scaricata dal Play Store ufficiale Android.
Anche le analisi riguardanti il traffico di rete sono state effettuate in modo passivo, ovvero osservando esclusivamente ciò che l’applicazione invia al suo server durante il normale utilizzo. Nessuna richiesta di rete è stata manipolata e/o inviata in maniera arbitraria al server. Ovviamente conservo il dump del traffico generato durante l’analisi a supporto delle mie affermazioni.
Insomma, per dirlo con un’altra parola stra-abusata a sproposito: non è stato “hackerato” niente.
L’APPLICAZIONE RICICLATA
Dillo a Clemente, distribuita sugli store Apple e Android con il nome Mastella è stata “sviluppata” da Analist Group s.r.l. di Avellino in Xamarin, una piattaforma di sviluppo mobile che consente di scrivere codice C# (C Sharp) che è un linguaggio di programmazione dell’ecosistema .NET di Microsoft.
Ho virgolettato “sviluppata” non a caso, perché sia l’app che il back-end (l’applicazione lato server con cui comunica l’app che gira sul vostro telefono) sono un’accozzaglia di codice proveniente da altre applicazioni e riutilizzate in malo modo.
Attenzione: seppure questa affermazione è sicuramente vera per la parte client (l’app appunto), non può essere verificata per quanto riguarda il back-end poiché il codice gira sul server e non è possibile “scaricarlo”. Ci sono però degli elementi che lo lasciano pensare.
L’applicazione riciclata per creare “Mastella” si chiama “Instanteat”, ovviamente sempre sviluppata da Analist Group, e la trovate sul Play Store e Apple Store.
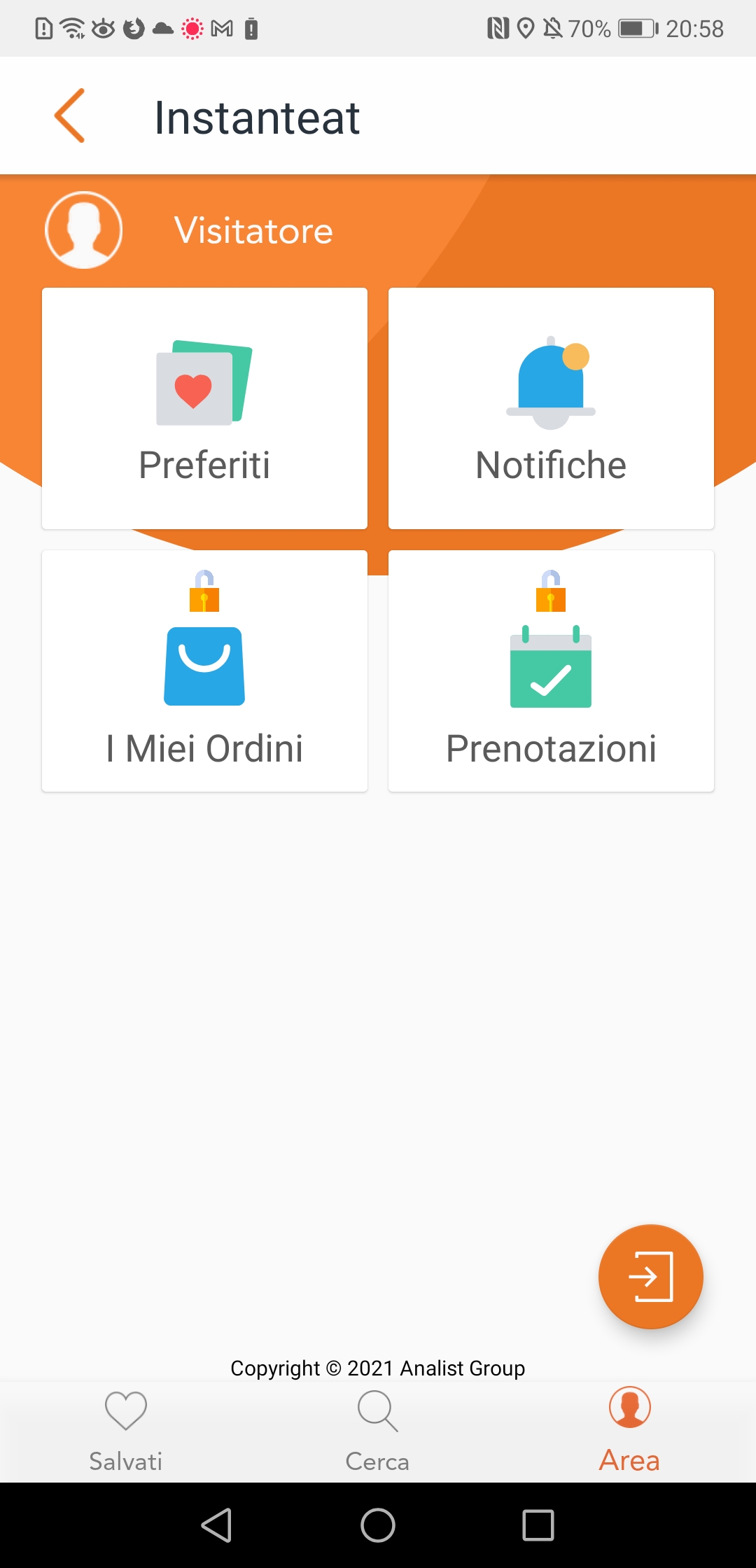
Provate a cliccare sull’icona in basso a destra dell’app “Mastella”, vi verrà fuori un menu che non ha molto a che fare con la funzionalità dell’app.
Schermata dell’app Mastella cliccando sull’icona in basso a destra a forma di omino
Schermata dell’app Instanteat cliccando sull’icona in basso a destra “Area”
Qualcuno potrebbe obiettare che non si tratta di riciclo, ma della nobile arte di riutilizzo di codice tramite il medesimo framework applicativo. No, fidatevi, è roba riciclata e anche male.
Il bucket S3 utilizzato da “Mastella” per memorizzare gli asset statici (le immagini ad esempio), è lo stesso di “Instanteat”: instanteat.s3.eu-central-1.amazonaws.com.
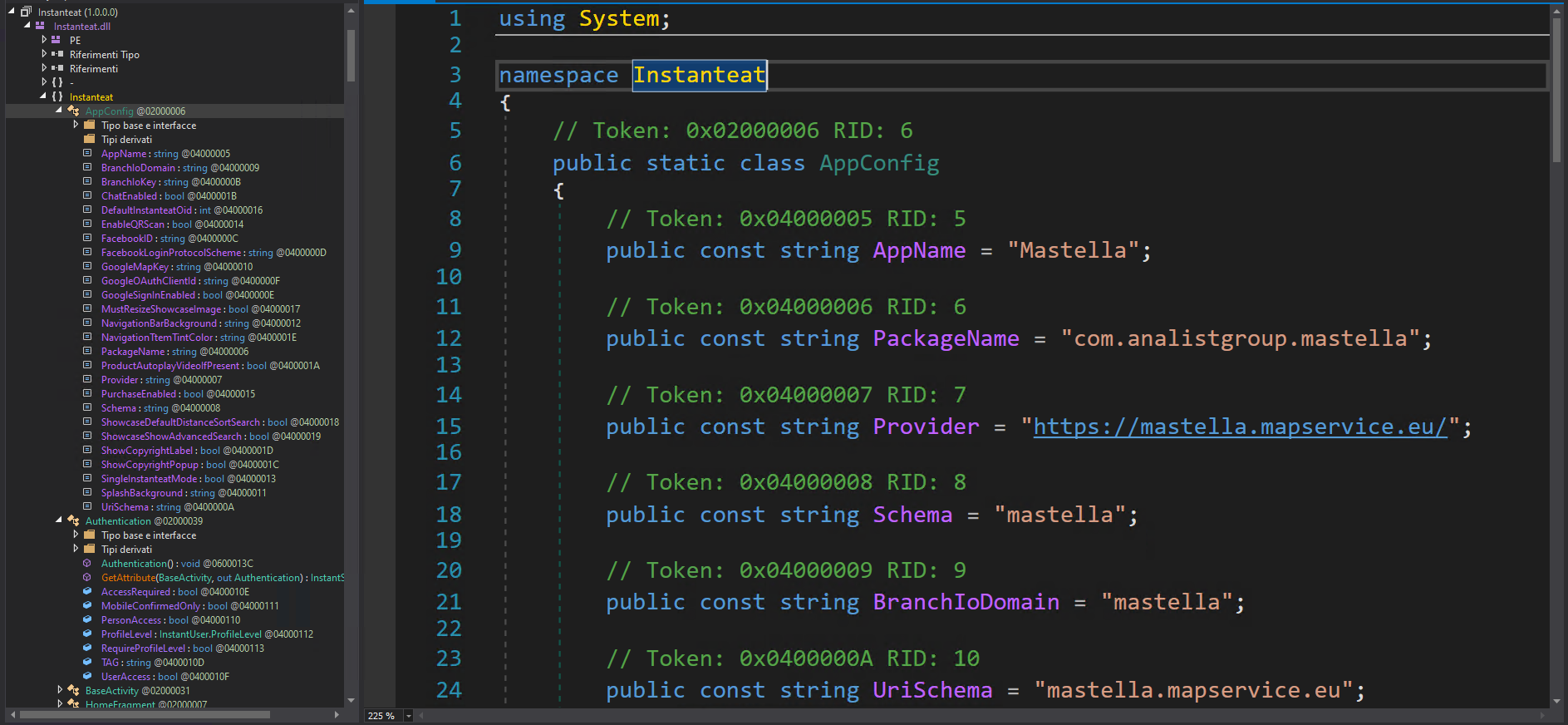
Non siete ancora convinti? Bene, il namespace dell’applicazione “Mastella” è proprio “Instanteat”, e il codice sorgente è compilato nel file col nome “Instanteat.dll”.
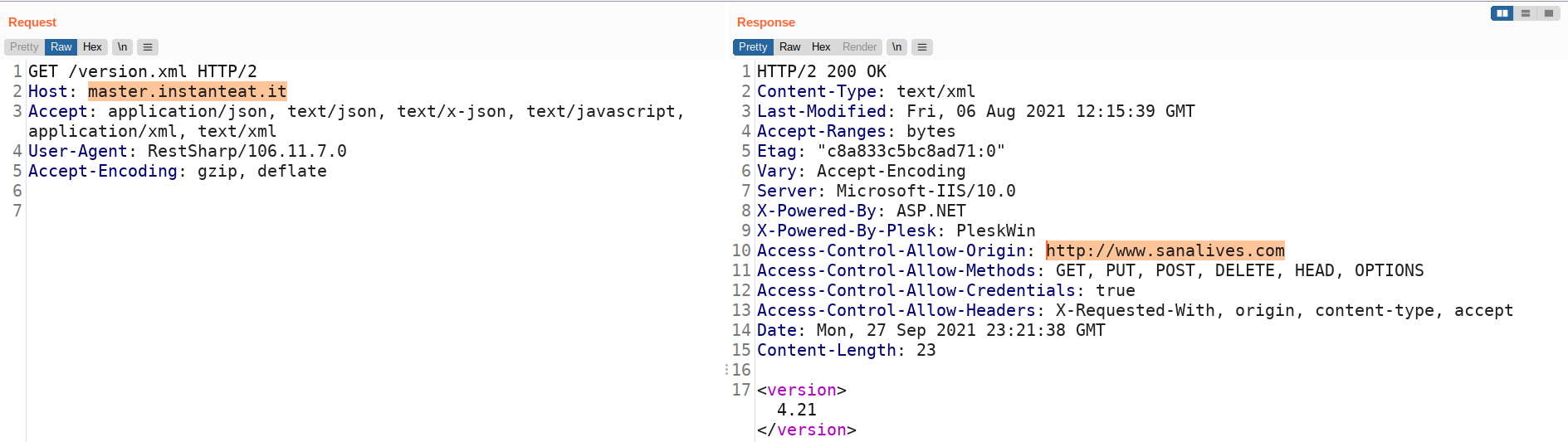
Imho, hanno clonato il repository dell’app Instanteat contenente l’intera solution (sono ottimista, non voglio pensare sia solo una banale cartella condivisa in rete), sostituito il nome da “Instanteat” a “Mastella”, il package name da “com.analistgroup.instanteat” a “com.analistgroup.mastella”, l’indirizzo del backend da “master.instanteat.it” a “mastella.mapservice.eu” più altre cosucce, disabilitato alcune voci di menu, buildato senza rimuovere il resto del codice inutilizzato, e pubblicato il tutto in fretta e furia per la presentazione in pompa magna durante la campagna elettorale.
Decompilato C# di “Instanteat.dll” proveniente dal package android “Mastella”. Notare il namespace.Classi dell’applicazione “Mastella”, notare i nomi delle classi.
Se “Mastella” non ha lo scopo di prenotare il ristorante, “Instanteat.Agenda.Restaurant.Booking” non ha ragione d’essere, e se “Instanteat” voleva essere un framework, è ben lontano da esserlo.
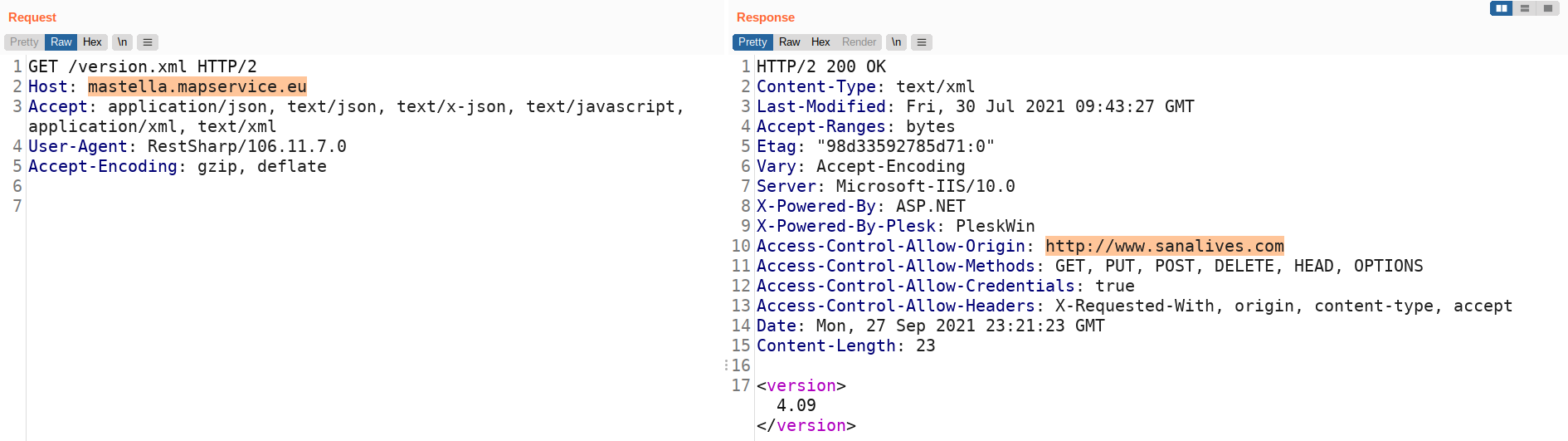
Ma diamo un occhio anche alle risposte ritornate dal back-end alle nostre due app, fate caso all’header Access-Control-Allow-Origin che dovrebbe regolare il funzionamento delle CORS:
Nel back-end di “Mastella” c’è un riferimento a http://www.sanalives.comLo stesso riferimento a http://www.sanalives.com è presente nella risposta del back-end di “Instanteat”Il sito SanaLives è di Analist Group
Alla fiera di .(dot)NET, per due soldi, un repository lo sviluppatore clonò […] E venne Mastella che clonò Instanteat, che clonò SanaLives, che per due soldi Analist Group sviluppò… (Si scherza eh… – NdR)
INTELLIGENZA FECALE
No, seriamente. Le parole “Intelligenza artificiale” sono usate a sproposito. Accade spesso tra i non addetti ai lavori, ma questo caso è eclatante.
Cosa fa l’app? Quali sono le sue funzionalità?
Tralasciamo pure il menu accessibile dall’icona in basso a destra, quella a forma di omino, che porta alla schermata con le icone “Preferiti”, “Notifiche”, “I Miei Ordini”, “Prenotazioni” (cosa, il ristorante? 🙂 ) Di queste cose non funziona niente, almeno ad oggi.
Cosa rimane? La schermata principale con l’icona del microfono con cui è possibile parlare con Clemente grazie all’intelligenza artificiale che capirà ciò che diciamo e ci risponderà in modo sensato. NO! NO! NO! NOOOO! CAZZO NO!
L’iconcina del microfono non fa altro che utilizzare una funzionalità di Google* (non di Mastella e non di Analist Group) che si chiama speech-to-text. Questa funzionalità già presente nei nostri smartphone (la stessa che usa l’assistente vocale quando dettiamo un messaggio, ad esempio) si occupa di trasformare quello che diciamo in testo. Fine.
*Sì, le funzionalità speech-to-text e text-to-speech di Google migliorano la propria precisione grazie anche al Machine-Learning. Ma questa è un’altra storia che non ha nulla a che vedere con l’app “Mastella”.
Dopo tale lavoro effettuato da una libreria di Google (nella versione Android dell’app), il testo generato da quest’ultima viene recuperato dall’app “Mastella” e inviata al back-end (server).
Il server controlla se il testo da noi inviato è presente tra quelli inseriti a mano dagli sviluppatori dell’app. Se lo è ci risponde con la risposta associata (anch’essa inserita a mano dagli sviluppatori), una supercazzola. Se la domanda da noi inviata non è presente o non è formulata nella maniera esatta a quella inserita dagli sviluppatori, l’app ci risponde che ha capito e ci farà sapere.
Le domande che possiamo fargli, quindi, sono limitate a quelle inserite nel server. Né l’applicazione, né il back-end hanno la capacità di “capire” quello che gli stiamo chiedendo.
Sul sito ufficiale, cliccando sul pulsante giallo “Cosa puoi chiedermi” parte un MP3 (sì, avete capito bene, un ormai vintage MP3) che ci “suggerisce” cosa possiamo chiedergli, ovvero le domande che gli sviluppatori (o lo staff) hanno inserito e a cui hanno associato una supercazz… ehm, una risposta: https://www.dilloaclemente.it/mp3/clemente-richiesta-3.mp3
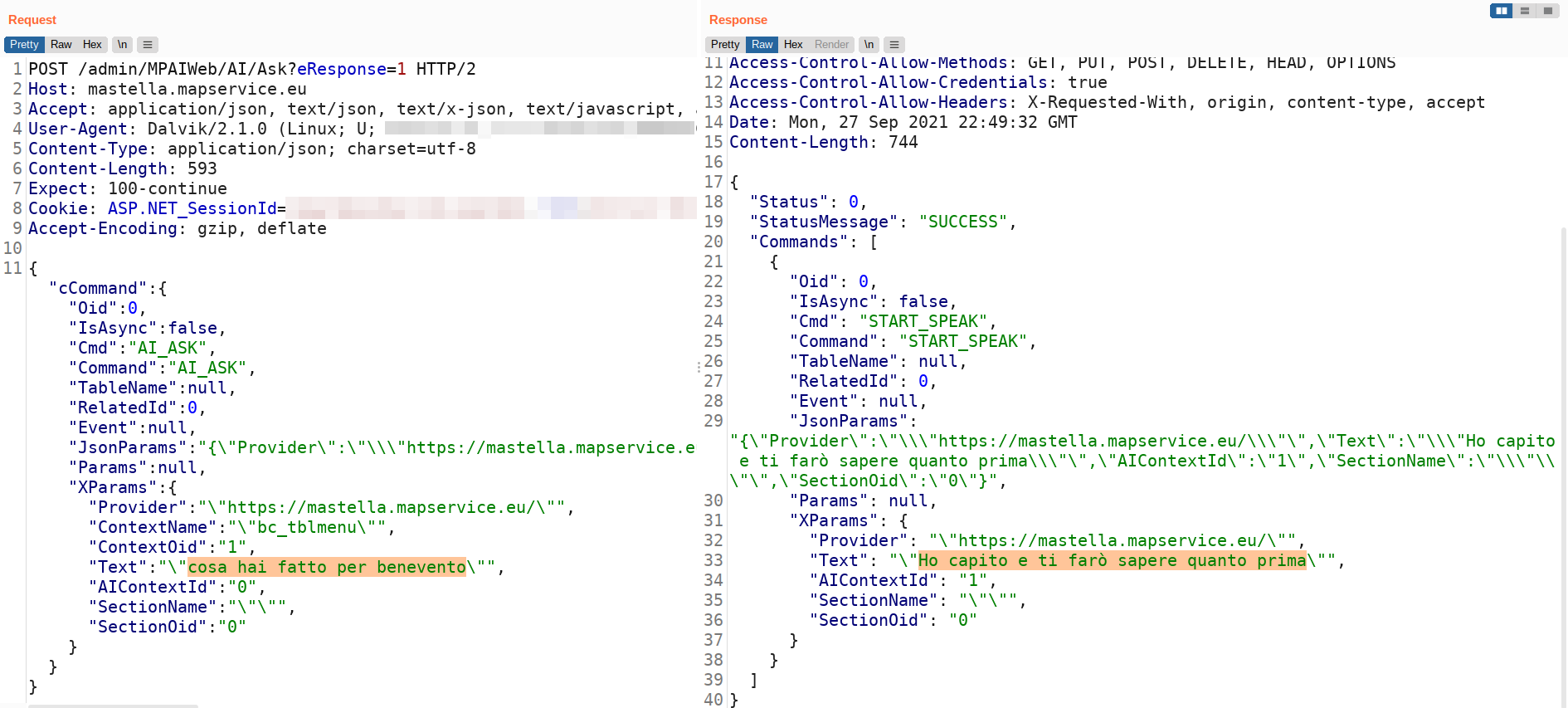
Richiesta HTTP inviata dall’app (a sinistra) e risposta del server (a destra)
Bene, adesso provate a formulare la domanda in maniera leggermente diversa, esempio: “Cosa hai fatto per Benevento?” La risposta sarà un triste “Ho capito e ti farò sapere quanto prima”. Le faremo sapere, insomma.
Cosa hai fatto per Benevento? Niente.
Dev’essere veramente molto stupida questa intelligenza artificiale. No! Non c’è alcuna intelligenza artificiale!
Semplicemente hanno associato alle parole “fatto per la città” quella risposta. Prima di quella sequenza potete dire qulasiasi altra cosa, vi risponderà sempre la solita supercazzola, ma se cambiate anche solo una parola della sequenza da loro cablata, non troverà alcuna risposta all’interno del database.
Indovinate cosa risponde a: “Supercalifragilistichespiralidoso, anche se a sentirlo può sembrare spaventoso, se lo dici forte avrai un successo strepitoso, fatto per la città“?
Supercazzola!
GEOLOCALIZZAZIONE
Una cosa l’app la fa bene: geolocalizzarvi e inviare la vostra posizione geografica al server.
“Tranquilli”, non lo fa in background (mentre l’applicazione è chiusa), ma lo fa ogni qual volta aprite l’app, cliccate qualsiasi cosa in giro, oppure in autonomia ogni minuto che l’app rimane aperta.
La posizione inviata al server è precisa con risoluzione di pochi metri, perché l’app la recupera dal GPS del telefono.
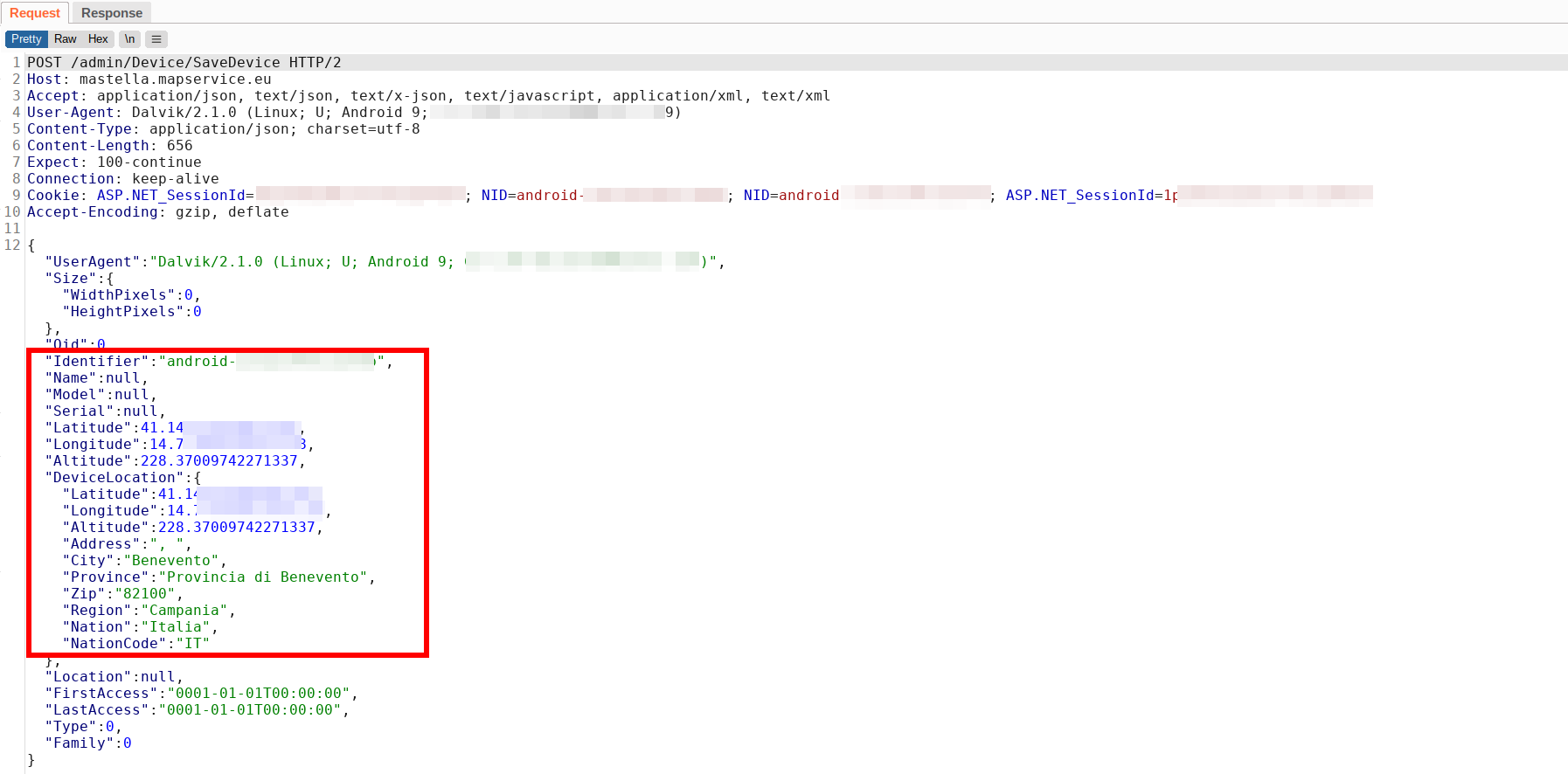
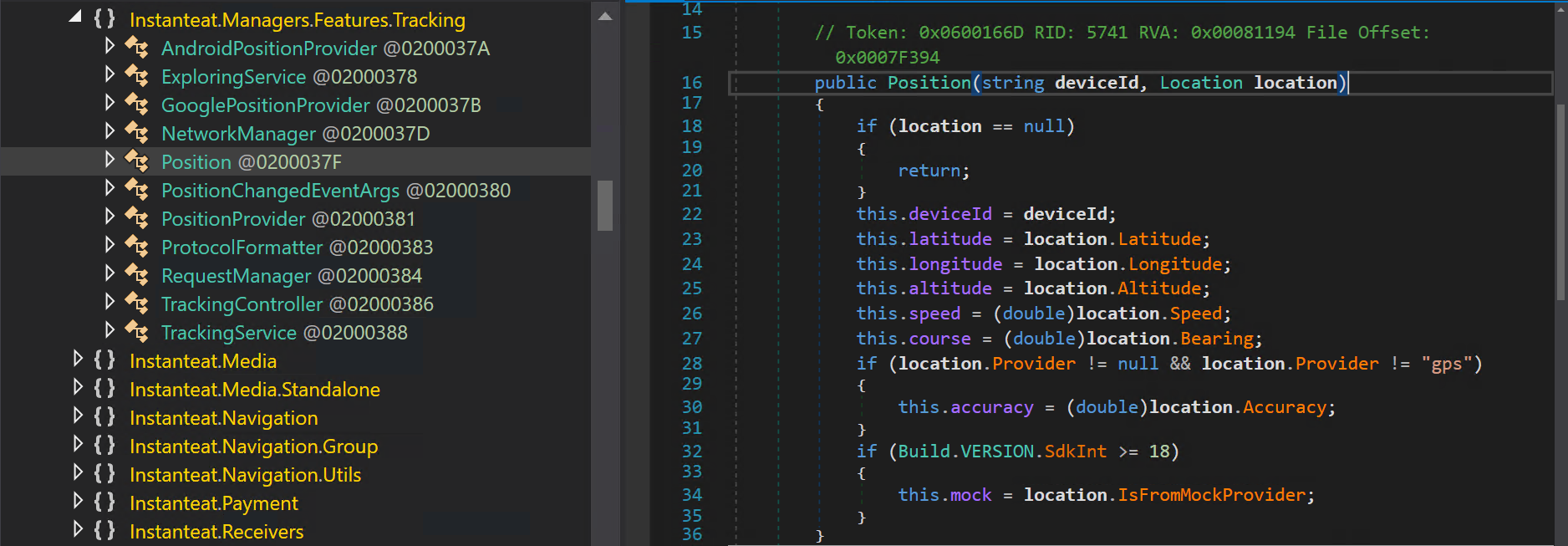
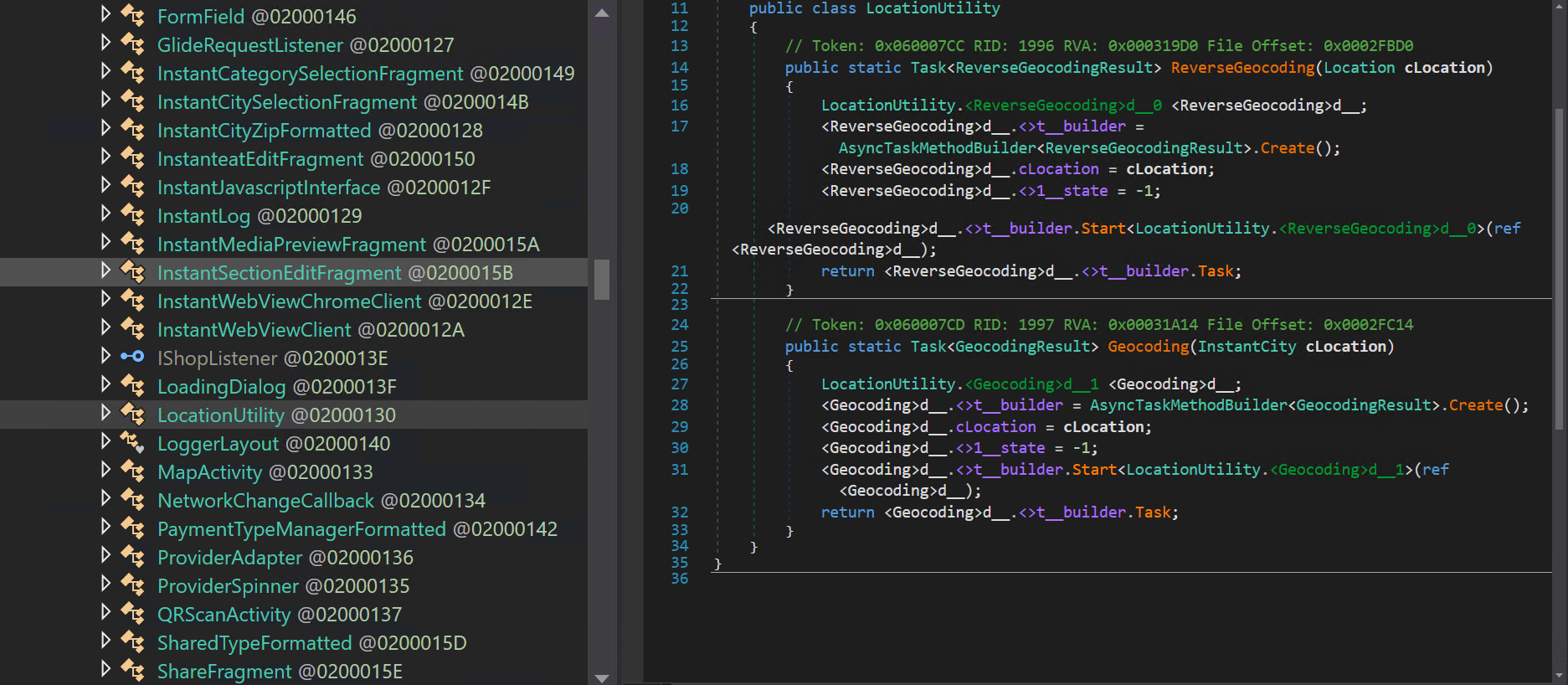
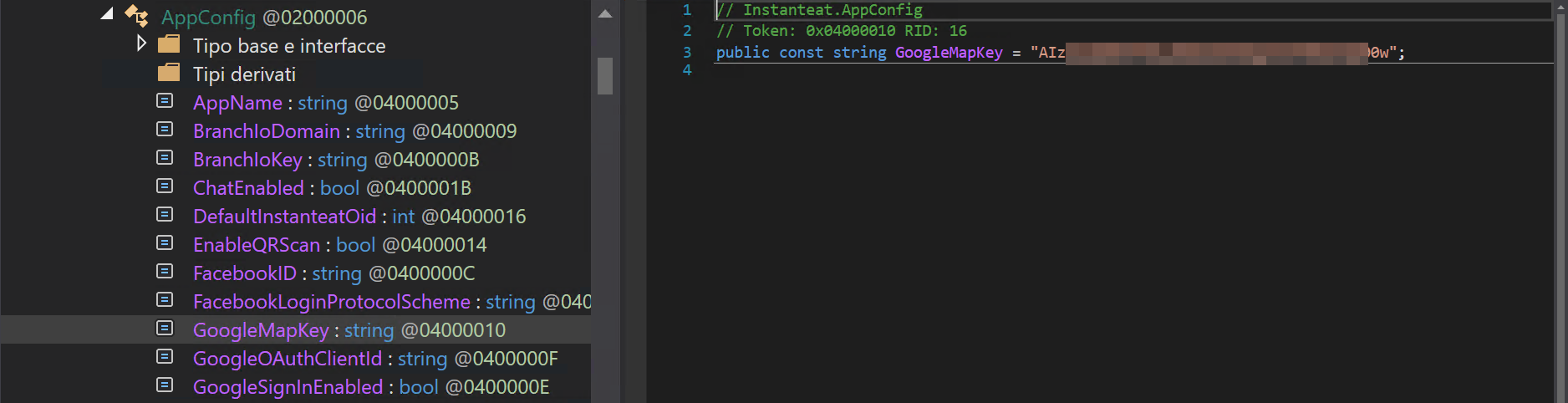
Non solo vengono inviate le coordinate latitudine, longitudine, e altitudine, ma l’applicazione usa anche un’API di Google Maps per effettuare il “reverse” e recuperare l’indirizzo (via, città, provincia). Tra l’altro effettua questa operazione “client-side”, facendo disclosure dell’API-Key utilizzata per autenticarsi a tale servizio 😳 .
Assieme ai dati di geolocalizzazione l’app invia un identificativo univoco del nostro dispositivo, il suo UserAgent, ed è predisposta ad inviare anche il nome, il modello e il numero seriale (funzionalità che pare non funzionare).
La richiesta che l’app invia al server ogni minuto o ad ogni click: notare le coordinate geografiche, l’indirizzo, l’identificativo univoco del dispositivo, e i cookie con l’ID univoco di sessione.
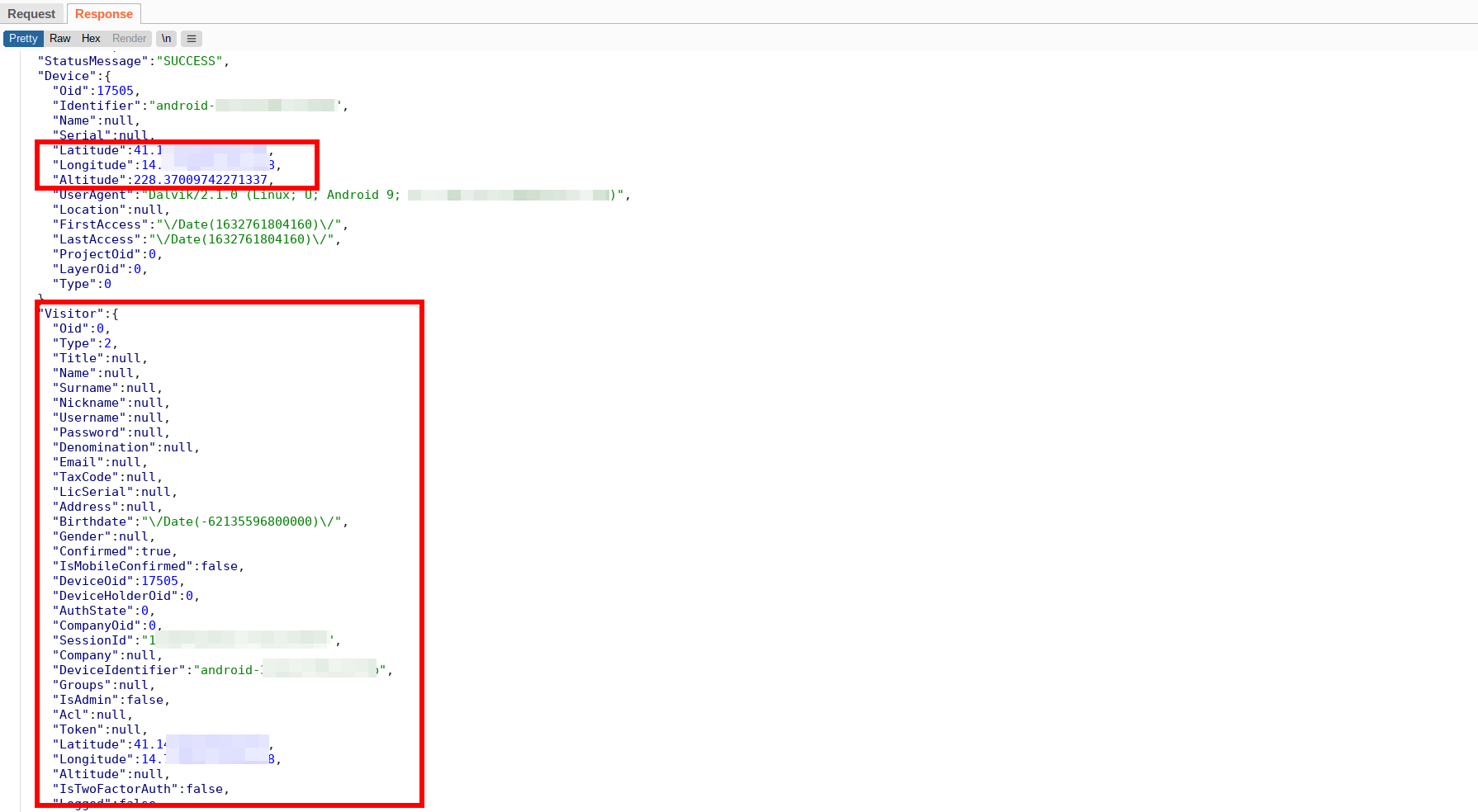
La risposta che il server invia all’app contiene i campi: nome, cognome, username, password 😳 , email, data di nascita, e codice fiscale. Al momento tali parametri sono vuoti poiché l’applicazione non prevede che l’utente si registri ed effettui un login, ma potrebbero essere disponibili in futuro.
La risposta del server recupera e ritorna ulteriori dati dell’utente dalla sessione in corso.Parte del codice sorgente che si occupa della geolocalizzazione. Classe “Instanteat.Managers.Features.Tracking”.Parte del codice che si occupa del “Reverse Geocoding” tramite le API di Google Maps.Disclosure dell’API-Key, RTFM.
PRIVACY POLICY
Non pervenuta. L’app e il sito non avvisano che viene raccolta la posizione geografica precisa (tramite GPS) e inoltrata ai server di Analist Group.
Certo, gli altri dati come nome, cognome, ecc, sono vuoti. C’è però l’ID univoco del dispositivo e un bel cookie di sessione (e ovviamente il nostro indirizzo IP).
Qualora l’app, anche in futuro, dovesse far funzionare le già presenti aree di registrazione e login, Analist Group sarebbe in grado di de-anonimizzare tutti i dati, anche quelli passati, inviati fino ad ora in forma pseudo-anonima >:( .
Oltre al discorso della geolocalizzazione l’app utilizza 7 tracker, di cui l’utente dovrebbe essere informato:
Ci sono gli estremi per fare un esposto al Garante della privacy? Penso proprio di sì.
A questo link trovate la privacy policy linkata al sito “dilloaclemente.it”, e il suo mirror.
CONCLUSIONI
Questo post non è e non vuole essere un attacco politico a Mastella né tantomeno all’azienda Analist Group.
Frega un cazzo della campagna elettorale. Non ho amici candidati e di solito il mio voto finisce in quella percentuale insignificante tra l’1 e il 4%, quindi no, non mi paga la concorrenza!!1!1!.
Riguardo Analist Group: non li conosco, non mi sono antipatici, e non siamo in concorrenza. Non faccio app, il mio ambito è totalmente diverso.
Quello che attacco è l’uso e l’abuso delle buzzword come in questo caso “Intelligenza Artificiale”, soprattutto se lo scopo di tale utilizzo è quello di ingannare l’elettorato medio facendo leva sulla non conoscenza in merito ad argomenti complessi.
L’altra cosa antipatica è il non rispetto della privacy.
La tecnologia messa a disposizione dall’ecosistema mobile è potente. Lavorare con dati, metadati, e profilazione può sembrare “banale” visto le interfacce semplici esposte dai dispositivi e dalle librerie. Ma non lo è, perché prima di giocare con queste cose bisogna studiare, e prima ancora bisogna avere rispetto delle persone.
RIPRODUCIBILITÀ DELL’ANALISI
Il seguente post è stato scritto analizzando l’app “Mastella” versione 6.32 scaricata dal Play Store ufficiale Android.
The affected vendor did not answer to my responsible disclosure request, so I’m here to disclose this “hack” without revealing the name of the vendor itself.
The target machine uses an insecure NFC Card, MIFARE Classic 1k, that has been affected by multiple vulnerabilities so should not be used in important application. Furthermore, the user’s credit was stored on the card enabling different attack scenarios, from double spending to potential data tamper storing an arbitrary credit.
Useful notes from MIFARE Classic 1K datasheet:
EEPROM: 1 kB is organized in 16 sectors of 4 blocks. One block contains 16 bytes. The last block of each sector is called “trailer”, which contains two secret keys and programmable access conditions for each block in this sector.
Manufacturer block: This is the first data block (block 0) of the first sector (sector 0). It contains the IC manufacturer data. This block is read-only.
Data blocks: All sectors contain 3 blocks of 16 bytes for storing data (Sector 0 contains only two data blocks and the read-only manufacturer block). The data blocks can be configured by the access conditions bits as:
Read/Write blocks: fully arbitrary data, in arbitrary format
Value blocks: fixed data format which permits native error detection and correction and a backup management. A value block can only be generated through a write operation in value block format:
Value: Signifies a signed 4-byte value. The lowest significant byte of a value is stored in the lowest address byte. Negative values are stored in standard 2´s complement format. For reasons of data integrity and security, a value is stored three times, twice non-inverted and once inverted.
Adr: Signifies a 1-byte address, which can be used to save the storage address of a block, when implementing a powerful backup management. The address byte is stored four times, twice inverted and non-inverted.
Value block example for value 0x0012D687
Let’s start hacking:
In this post I did not show you how to crack the MIFARE Classic Keys needed to read/write the card, ’cause someone else has already disclosed it some time ago, so google is your friend. At last, please, use this post to skill yourself about the fascinating world of reverse engineering, and not for stealing stuffs.
In order to start the analysis I need some dump to compare. The requirements of this task are nfc-mfclassic tool included in libnfc, a NFC hardware interface like ACR122U, and a binary compare (aka binarydiff) tool like dhex.
Dumps:
Dump 0: Virgin card (not included in the screenshot below ’cause all data bytes were 0x00, except for the sector 0 that has UID and manufacturer information. These sector is read only, so these bytes are the same across dumps)
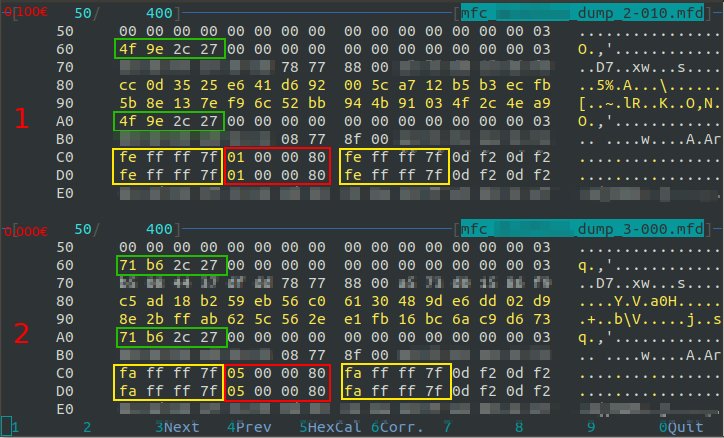
Dump 1: Card charged with single 0.10€ coin (Note that vending machine displays the balance with 3 decimals, 0.100€)
Dump 2: 0.00€ after spending the entire balance with 4 transactions of 0.025€ each
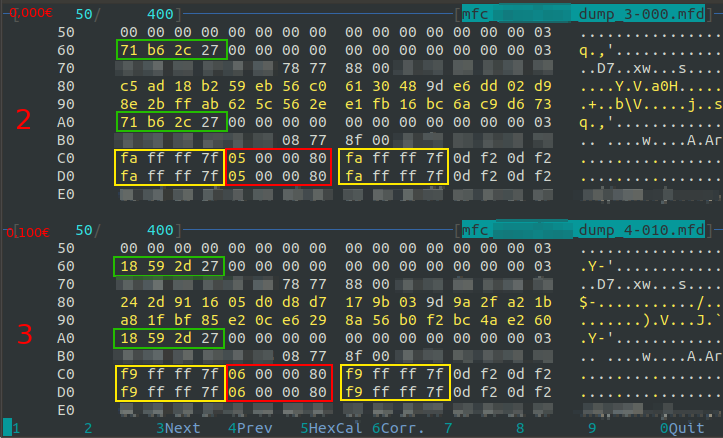
Blurred bytes are the MIFARE keys A and B, except for the 32 bytes at 0xE0 offset of which I don’t know their purpose. The 4 bytes between the keys are Access Condition and denotes which key must be used for read and write operation (A or B key) and the block type (“read/write block” or “value block”).
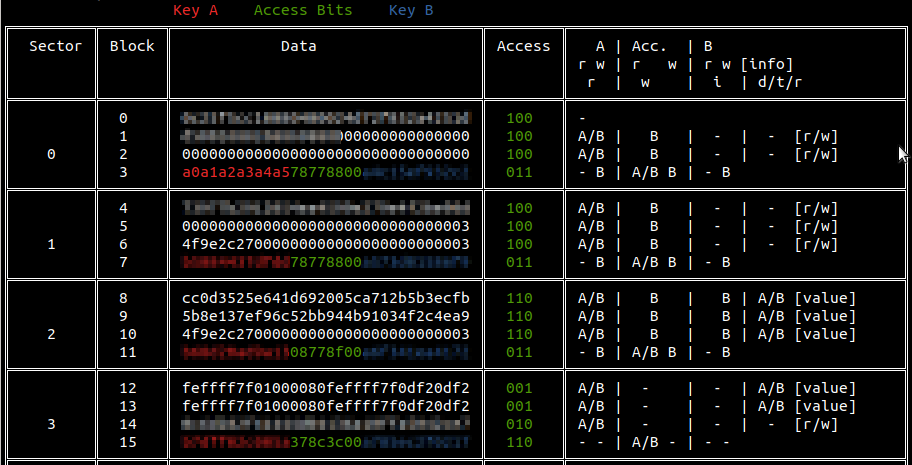
The tool mfdread is useful to decode the Access Condition bytes rapidly, and, in general, to display MIFARE Classic data divided by sectors and blocks:
Dump 1 with mfdread parser
Early analysis:
Note: from now on I will refer to the offsets with a [square parenthesis] and a value with no parenthesis.
Blocks 8, 9, 10, 12 and 13 can be used also as “value block”
Except for bytes between offsets [0x80] and [0x9F], only few bytes differ between dumps
Some data are redundant, for example [0x60 … 0x63] has the same values of [0xA0 … 0xA3]
Values at [0xC0], [0xD0], [0xC8], [0xD8] differ by 4 between 1st and 2nd dump (eg: 0xFE – 0xFA = 0x4) and differ by 1 between 2nd dump and 3rd dump (eg: 0xFA – 0xF9 = 0x1)
Values at [0xC4], [0xD4] differ by 4 between 1st and 2nd dump (eg: 0x05 – 0x01 = 0x4) and differ by 1 between 2nd and 3rd dump (eg: 0x06 – 0x05 = 0x1)
4 is the number of spent transaction made the first time, and 1 is the number of recharge transaction made the second time
Sum between yellow squared and red squared offsets has 0xFF value. In other words red squared is inverse (XOR with 0xFF) of yellow squared. For example:
0xFE ⊕ 0xFF = 0x01
0xFF ⊕ 0xFF = 0x00
…
0x7F ⊕ 0xFF = 0x80
Values at [0x60 … 0x63] are a UNIX TIMESTAMP in little endian notation:
Ok, we are not in the 90ies, but the time difference between transactions is correct, maybe the vending machine doesn’t have an UPS 🙂
Early findings:
Timestamp of the last transaction was stored as 32 bit integer at MIFARE block 6 and redundant at at MIFARE block 10
Only MIFARE blocks 12 and 13 has “Value block” format, and they are used to store the counter of remain transaction in 32 bit format. This counter starts from 0x7FFFFFFF (2.147.483.647) and is decreased at each transaction
Blocks 1, 4, and 14 contains some data that are fixed between dumps
Blocks 8 and 9 changes entirely at each transaction
The credit:
If there is credit stored on the card, it was encoded at blocks 8 and 9, and the number of bytes involved between small credit difference (for example between 0.00€ and 0.10€) could indicate that some cryptographic function is involved.
At this time, a double spending attack could confirm if the credit is really stored on the card. So, after spending all the credit, I have rewritten a previous dump on the card and I went to test it at the vending machine. The card was fully functional with the previous credit stored in that dump. Now, I’m certain that the credit is encoded (and probably encrypted) in the blocks 8 and 9.
Conclusion:
Even if the encoding format of the credit is still unknown, a double spending attack was possible.
This means that the vendor’s effort to obfuscate the credit is nullified 🙁
Adding some unique token on the card that are invalidated into back-end after each transaction, means that this token needs to be shared between all the vending machines of the vendor, but, if we add internet connection to the vending machine, there is no longer reason to store the credit on the card.
So, after all, the only remediation action that makes sense is: DO NOT STORE THE CREDIT ON THE CARD! And, more generally: DO NOT TRUST THE CLIENT!
Road to arbitrary credit:
Spending 1€ infinite times isn’t the scope of that hack. The only real scope is FUN! To continue this analysis I need to collect a large number of dumps to advance some hypothesis so, when I have other material I will make another post.
An example of easier card:
Some vendor has more easier approach by using the MIFARE “Value block” to store the credit without obfuscation or encryption.
Credit stored on the MIFARE Value Block
The above screenshot made with “MIFARE Classic Tool” on Android smartphone, represents a Value Block used to store the credit:
0x00000CE4 = 3300 is the value in Euro thousandths (3.30€).
This particular vendor do not use key A and the Key B is a default key 0xFFFFFFFFFFFFFFFF, so the attacker doesn’t need to crack anything.
Reverse engineering and cracking of a Vending Machine is always funny 🙂














{kind=link}